Smoothness Errors in Dynamics Models and How to Avoid Them
International Conference on Machine Learning 2026 (ICML 2026)
Abstract: Modern neural networks have shown promise for solving partial differential equations over surfaces, often by discretizing the surface as a mesh and learning with a mesh-aware graph neural network. However, graph neural networks suffer from oversmoothing, where a node's features become increasingly similar to those of its neighbors. Unitary graph convolutions, which are mathematically constrained to preserve smoothness, have been proposed to address this issue. Despite this, in many physical systems, such as diffusion processes, smoothness naturally increases and unitarity may be overconstraining. In this paper, we systematically study the smoothing effects of different GNNs for dynamics modeling and prove that unitary convolutions hurt performance for such tasks. We propose relaxed unitary convolutions that balance smoothness preservation with the natural smoothing required for physical systems. We also generalize unitary and relaxed unitary convolutions from graphs to meshes. In experiments on PDEs such as the heat and wave equations over complex meshes and on weather forecasting, we find that our method outperforms several strong baselines, including mesh-aware transformers and equivariant neural networks.
 |
 |
 |
 |
| Edward Berman* | Luisa Li* | Jung Yeon Park | Robin Walters |
*Equal contribution
Geometric Learning Lab, Khoury College of Computer Sciences, Northeastern University
Motivation
Dynamical systems on surfaces are ubiquitous, and graph neural networks are often used to solve them, but these often suffer from oversmoothing. Unitary convolution [1] preserves smoothness, but this is over constraining in most dynamical systems.
Goals
- Derive approximation error bound to quantify the degree to which unitary functions can be over constraining in this setting.
- Develop relaxed unitary networks that more closely match the smoothness of labeled graphs/meshes for dynamics modeling.
- Extend unitary convolutions, relaxed unitary convolutions, and the Rayleigh quotient metric from graphs to meshes.
Background
Given an undirected graph \( \mathcal{G}=(V,E) \) and given a function from nodes to features \( s \colon V\to\mathbb{C}^d \), the Rayleigh quotient is defined as:
\[ R_{\mathcal{G}}(\mathbf{X}) = \frac{1}{2}\frac{{\sum_{(u, v) \in E}} \left\| \frac{s(u)}{\sqrt{d_u}} - \frac{s(v)}{\sqrt{d_v}}\right\|^2}{{\sum_{w \in V}} || s(w) ||^2} \]
Intuitively, the Rayleigh quotient measures the mean difference in node features for adjacent nodes. A graph with identical degree-weighted node features has a Rayleigh quotient of zero. The smoother the signal defined over the graph, the lower the Rayleigh quotient.
The Rayleigh quotient can also be defined in matrix form:
\[ R_{\mathcal{G}}(\mathbf{X}) = \frac{\text{Tr}{(\mathbf{X^\dagger(I - \tilde{A})X})}}{||\mathbf{X}||^2} \]
where \( \mathbf{A} \) is the adjacency matrix, \( \mathbf{D} \) is a diagonal matrix with the node degrees on the diagonal. Denote by \( \tilde{\mathbf{A}}= \mathbf{D}^{-1/2}\mathbf{AD}^{-1/2} \) the normalized adjacency matrix and \( \mathbf{X} \in \mathbb{C}^{n \times d} \) a matrix with the \( i \)-th row set to feature vector \( s(i) \).
Unitary Convolution [1] preserves the Rayleigh quotient! There are two unitary convolution variants, separable unitary convolution:
\[ f_{\rm UniConv}^{\mathrm{sep}}(\mathbf{X; A}) = \mathbf{\exp(iAt)XU}, \quad \mathbf{U^\dagger U =I} \]
and Lie unitary convolution
\[ f_{\rm UniConv}^{\mathrm{Lie}}(\mathbf{X;A}) = \mathbf{\exp(AXW)}, \quad \mathbf{W = - W^\dagger}. \]
[1] proves the following proposition:
Proposition: Unitary Convolution Preserves Smoothness
Both Lie or separable unitary convolutions preserves the Rayleigh quotient: \( R_{\mathcal{G}}(\mathbf{X}) = R_{\mathcal{G}}(f(\mathbf{X})) \)
Unitary convolution is overconstraining
Constraining our models to always preserve smoothness using unitary convolutions is an assumption that is sometimes overconstraining. We prove this theoretically and show this empirically via a motivating experiment.
In this experiment, we are looking to model heat diffusion over a grid graph. In this particular task, the signals defined on the graphs actually become smoother over time. We benchmark three models:
- A vanilla graph convolutional network, which [1] proved to oversmooth.
- A unitary convolution network, which strictly preserves smoothness.
- Our relaxed unitary convolution network (more on this later), which approximately preserves smoothness.
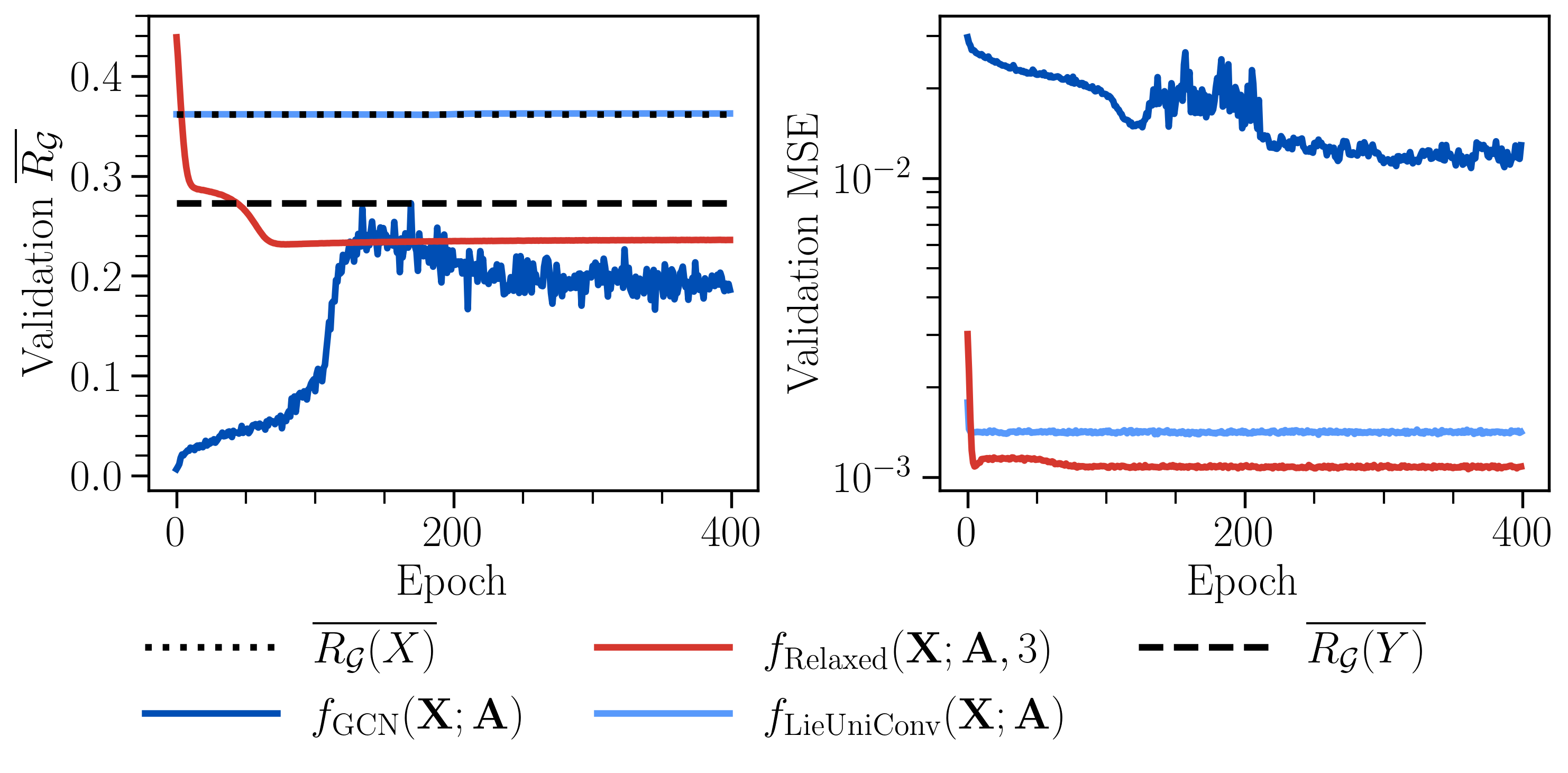
Our results show that the strictly unitary framework is overconstraining. It is unable to adapt to the smoothness (measured by the Rayleigh quotient) of the true dynamics. Similarly we show that a vanilla graph convolutional neural network does indeed oversmooth. Our relaxed unitary convolution network outperforms both the overconstrained and unconstrained counterparts.
To understand when unitarity is overconstraining, we derive an approximation error bound for unitary functions. We see that unitarity is especially overconstraining (and relaxations are the most useful) when the norm of the true function has a high angular variance.
Theorem: Approximation bound for unitary functions
Let \( F \) be a fundamental domain of \( \mathrm{SU}(n) \) in \( Z \), e.g. \( F = \{ t e \colon t \in \mathbb{R}_+\} \) where \( e \) is a standard basis vector of \( \mathbb{C}^n \). Let \(u \) be a unitary function. The approximation error of \( u \) of \( f \) has lower bound:
\[ \int_{Z}p(z)\lVert u(z) - f(z)\rVert_2^2dz \geq \int_{F} p(\lVert te \rVert) \mathbb{V}_{Gz}[\rVert f\lVert]dz. \]
Relaxed unitary convolution via Taylor truncation
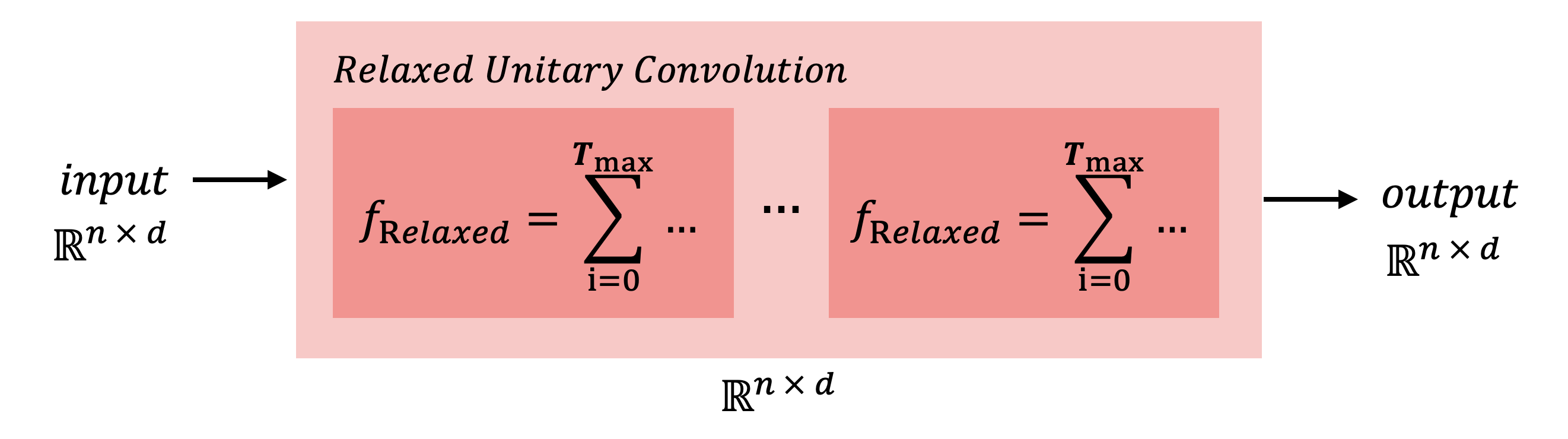
A simple way to relax unitary convolutions is early truncation of the Taylor series defining the exponential map. If the expected energy dissipation of the target PDE is known, then Taylor’s theorem can be used as a model selection criterion to select the appropriate \( \mathbf{T_{\rm max}} \) required to match smoothness without finetuning or grid search! This is the method that we used for our motivating experiment.
Extending from graphs to meshes
To make our insights on relaxed unitary convolutions more practical to real engineering domains, we generalize unitary convolutions, relaxed unitary convolutions, and the Rayleigh quotient from graphs to meshes. We also provide a second unitary convolution relaxation strategy that trades off fine-grained control for scalability.
To generalize the framework from graphs to meshes, we replace the standard degree normalized Laplacian in the Rayleigh quotient with the symmetric cotangent Laplacian as follows:
\[ \mathcal{W}_{ij} = \begin{cases} \frac{1}{2}\left(\cot \alpha_{ij} + \cot \beta_{ij}\right), & j \in \mathcal{N}(i)\\ -\displaystyle\sum_{k \in \mathcal{N}(i)} \mathcal{W}_{ik}, & i = j\\ 0, & \text{Otherwise.} \end{cases} \]
\[ R_{\mathcal{M}}(\mathbf{X}) = \frac{1}{2}\frac{\displaystyle\sum_{(u, v) \in \mathcal{E}} \mathcal{W}_{uv}\left\| \frac{s(u)}{\sqrt{d_u}} - \frac{s(v)}{\sqrt{d_v}}\right\|^2}{\displaystyle\sum_{w \in V} \left\| s(w) \right\|^2} = \frac{\text{Tr}(\mathbf{X}^\dagger \tilde{L} \mathbf{X})}{\|\mathbf{X}\|^2_F} \]
This definition of the Rayleigh quotient takes into account the curvature of the underlying manifold in the edge weights. We define unitary mesh convolutions using the same edge weights in the adjacency matrix:
\[ f_{\rm UniMeshConv}^{\mathrm{Sep}}(\mathbf{X;A}, \mathcal{W}) = \exp(i\, \tilde{\mathbf{A}})\mathbf{X U} \]
\[ f_{\rm UniMeshConv}^{\mathrm{Lie}}(\mathbf{X;A}, \mathcal{W}) = \exp(\tilde{\mathbf{A}}\, \mathbf{X W}) \]
For a sufficiently “nice” mesh (a Delaunay mesh), we prove that unitary mesh convolution preserves the mesh Rayleigh quotient:
Corollary: Unitary mesh convolution preserves smoothness
Given a mesh \( \mathcal{M} \) with normalized adjacency matrix \( \mathbf{\tilde{A}} = \mathbf{D^{-1/2}}(\mathcal{W} \odot \mathbf{A})\mathbf{D^{-1/2}} \), the mesh Rayleigh quotient is invariant under normalized unitary or orthogonal graph convolution, i.e. \( R_{\mathcal{M}} (\mathbf{X}) = R_\mathcal{M} (f_{\rm UniMeshConv} (\mathbf{X})) \) where \( f_{\rm UniMeshConv} \) is either separable or Lie.
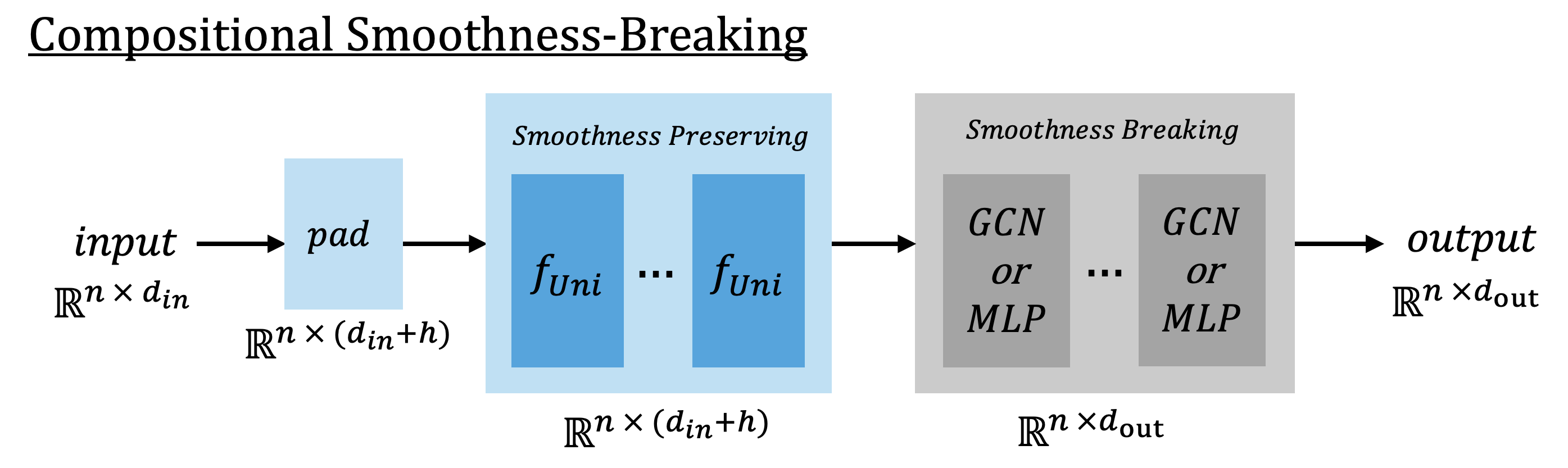
We next create an architecture by coupling these convolution layers with an unconstrained readout. Crucially, we use zero padding to increase the node feature dimension instead of using a learned embedding. Since unitary convolutions are constrained to preserve the feature dimension, this step is necessary to increase the number of parameters without making the network deeper. Zero padding also is useful because it preserves smoothness. We confirm the importance of this through ablation.
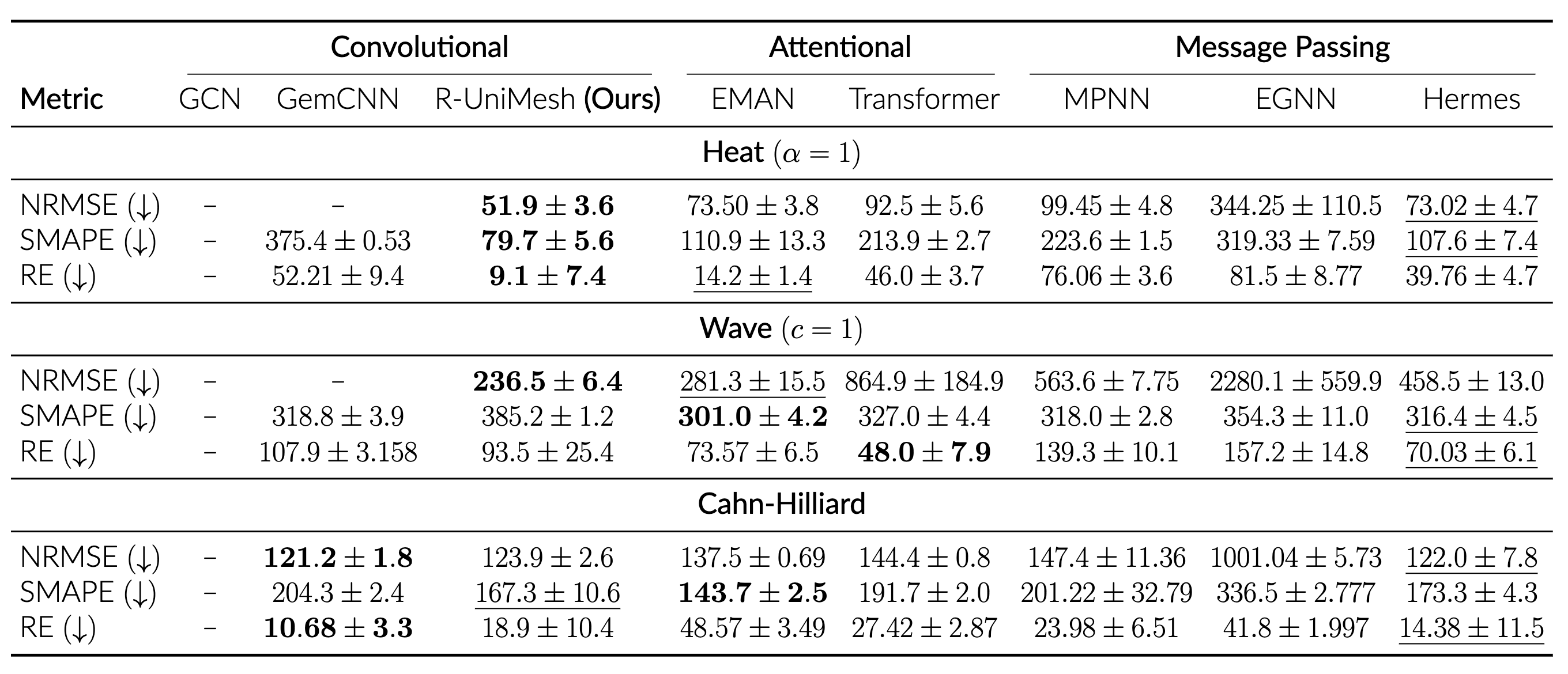
Our method is competitive with and exceeds strong baselines, especially for diffusive dynamics!
Future Work
- Extend to non-manifold meshes in order to incorporate boundary conditions.
- Explore architectures with a dynamic \( \mathbf{T_{\rm max}} \) to improve usability in systems with oscillatory smoothness.
- Incorporate boundary conditions in the PDE-solving framework.
References
- [1] Unitary Convolutions for Learning on Graphs and Groups, Kiani et al. NeurIPS 2024 Spotlight.
- [2] Unitary Convolutions for Message-passing and Positional Encodings on Directed Graphs, Fesser et al. ICML 2026.
- [3] Modeling Dynamics over Meshes with Gauge Equivariant Nonlinear Message Passing, Park et al. NeurIPS 2023.
Citation
@misc{berman2026smoothnesserrorsdynamicsmodels,
title={Smoothness Errors in Dynamics Models and How to Avoid Them},
author={Edward Berman and Luisa Li and Jung Yeon Park and Robin Walters},
year={2026},
eprint={2602.05352},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.05352},
}
come see us at the ICML poster session on july 9th, 2:30 PM – 4:15 PM, hall A, poster 63683